System and Method for Augmenting Channel Characteristics of Audio Recordings
Indian Patent #555374, issued 28 November, 2024.
U.S. Patent Pending.
Introduction
In today's era of artificial intelligence, the predominant focus has shifted from using data-lean small deep learning architectures to using data-hungry transformer architectures. This has made it increasingly challenging to develop effective systems for low-resource scenarios. My innovation addresses one such critical scenario: building robust machine learning models for diverse communication channels that have scarce data.
The Data Challenge in Audio Processing
Deep learning architectures have grown in popularity alongside large audio datasets. These datasets primarily consist of studio-recorded audio, containing samples captured under controlled environmental conditions. However, real-world communication often occurs through telephonic or similar channels, with each medium introducing its own unique vulnerabilities and characteristics. These characteristics significantly affect the audio signal quality. The impact varies by use case — whether casual conversation, military communication, or space transmissions.
Audio transmissions frequently contain noise and various distortions. These problems can originate at the source, particularly from poor acoustic conditions, or be introduced during the transmission process. This variability creates a significant challenge for machine learning. Developing solutions that can generalize across different communication mediums becomes extremely difficult. These solutions ideally shouldn't require massive amounts of channel-specific training data to be effective.
Understanding Communication Channel Vulnerabilities
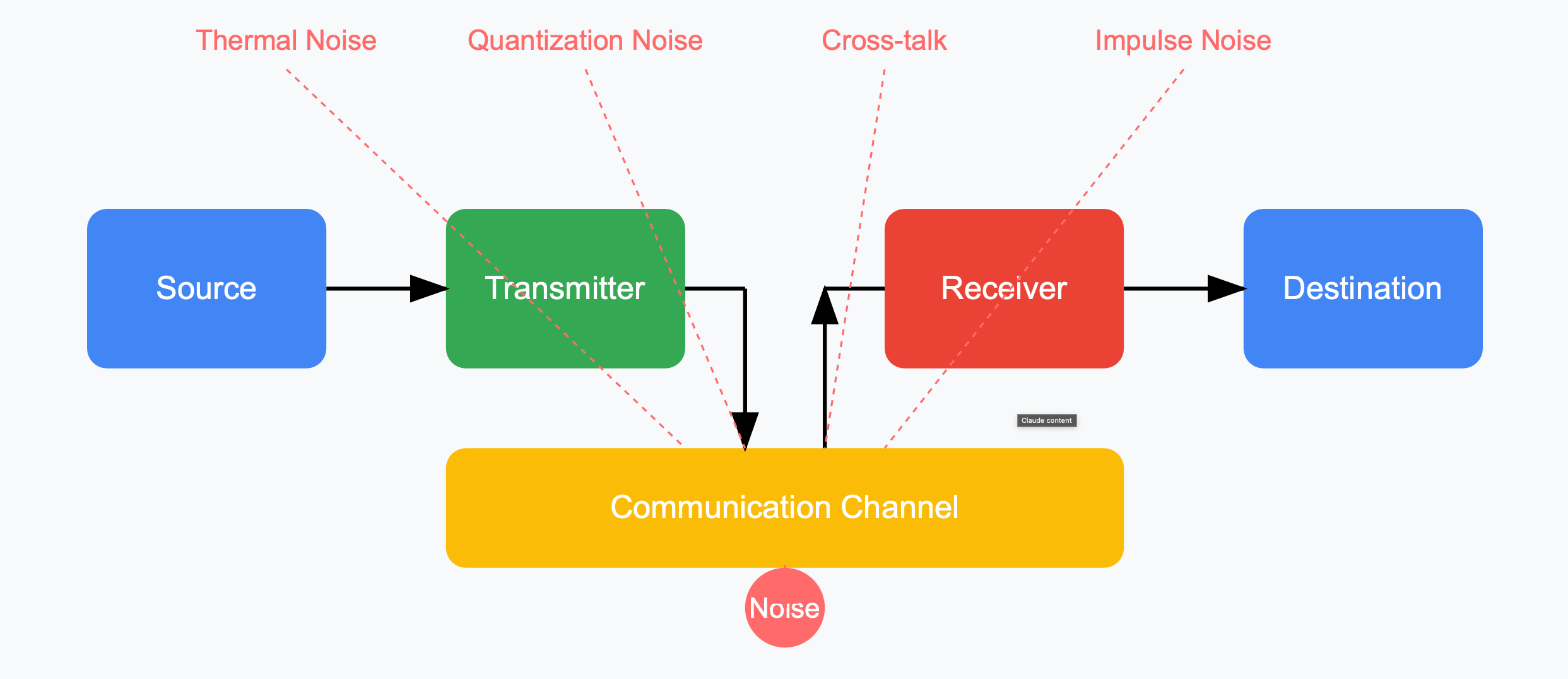
The diagram above illustrates the various vulnerabilities that can influence a communication channel. These vulnerabilities introduce disturbances to the source speech, which affects the signal quality at its destination. What arrives is a complex combination of the original signal and various forms of noise.
The critical insight of this innovation is that source signal, the added noise, and the received signal are not as correlated as they might seem. The typical noise modeling can be represented as:
Source Signal + Noise = Destination Signal
Most audio dataset creation methods for noisy environments rely on a such simplified equation. However, this approach is only effective with additive noise. In reality, the total noise of an audio signal is a stochastic process composed of varying amounts of additive noise and multiplicative (non-additive) noise.
Non-Additive Noise: The Complexity of Real-World Channels
While additive noise simply gets added to the system, non-additive noise can actually replace portions of the useful signal. This fundamental difference significantly impacts how we approach noise handling. When dealing with non-additive noise, predicting and removing it becomes more complex, as it's not merely layered on top of the original signal but becomes intrinsically woven into it. Examples of non-additive noise in communication channels include:
- Multiplicative Noise: Speckle noise is one example. Poor information channels often cause this type of noise. It multiplies with the original signals. This means it appears with the signals and disappears when pixel values reach zero.
- Channel-Specific Distortions: Broadcast stations create narrowband noise. Periodic impulsive noise can be both synchronous and asynchronous to the main frequency.
- Reverberation Effects: Sound reflects off surfaces in enclosed spaces. This creates multiple reflections of sound waves before they reach a listener. The result is complex time-frequency dependencies. These cannot be modeled as simple additive noise.
The Innovation: Mapping Acoustic Characteristics
This innovation offers a new way to understand and identify noise patterns in communication channels with limited resources. Rather than relying solely on the simplified additive noise model, the system implements:
- Channel Decomposition: A filter cascade of complex-valued filters decomposes the input audio signal into a plurality of frequency components or sub-band signals, which can be processed for phase alignment, amplitude compensation, and time delay.
- Characteristic Feature Extraction: The system extracts both time-domain and frequency-domain features that represent the complex interplay between the source signal and the channel effects. This includes spectral diversity characteristics and channel-specific coloration effects.
- Channel Behavior Modeling: The system uses multichannel transfer characteristics identified by source separation for reconstructing the real noise field and attenuating interference contributions.
- Augmentation Algorithm: The final part applies what the system learned about the channel to larger sets of data, creating realistic simulations of low-resource channel sound properties. This makes synthetic data that keeps the essential qualities of the target channel while using larger, more diverse datasets.
Applications and Benefits
This innovation has several practical applications:
- Speech Recognition in Adverse Conditions: Enabling more robust automatic speech recognition systems for telephonic, radio, or other communication channels with limited training data.
- Cross-Channel Adaptation: Improving the performance of multilingual acoustic models in low-resource settings through data augmentation techniques.
- Security and Intelligence Applications: Improves audio analysis for security purposes when people are communicating over poor-quality connections.
- Telecommunication Quality Improvement: Providing robust and efficient methods for noise reduction in audio signals transmitted via telecommunication channels.
Conclusion
This patent advances machine learning model building for low-resource audio channels. It moves beyond the additive noise model to understand channel characteristics, creating more realistic synthetic datasets. This bridges the gap between data-hungry deep learning architectures and the limited data availability for certain communication channels.
Through this algorithmic approach to acoustic characteristic mapping, developers can now augment large datasets with the specific properties of low-resource channels, enabling more robust and accurate models without requiring massive amounts of channel-specific data collection.